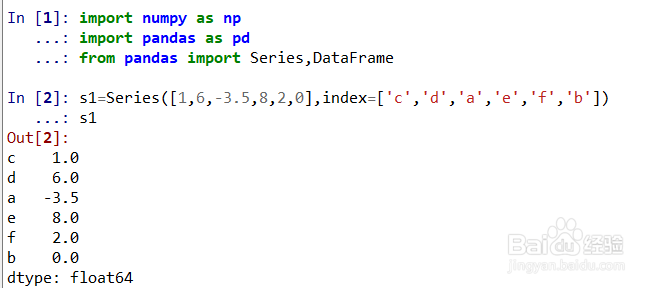
1、前提:加载numpy,pandas和Series,DataFrame。
生成一个Series,指定索引,具体如图
2、Series的按索引排序和按值排序。
分别使用s1.sort_index()和s1.sort_values()对s1按索引和值进行排序。
如图


3、Series如果有缺失值,那么用sort_values方法排序后,缺失值将会被放在Series的末尾,如图

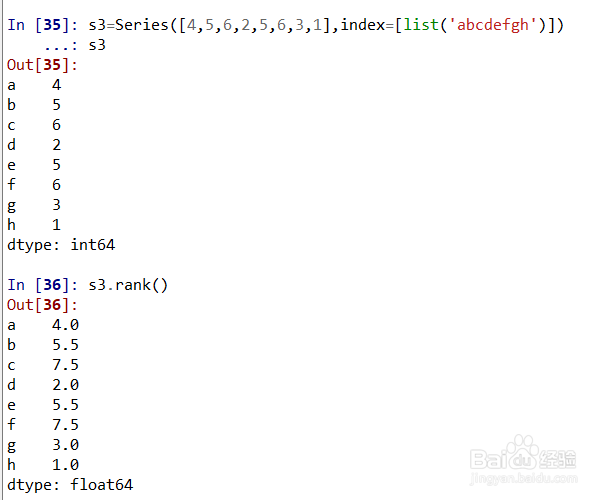
4、Series的排名。
这里新生成一个Series,名称是s3,
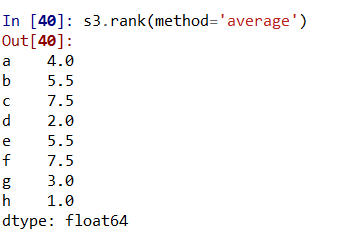
使用s3.rank()或s3.rank(method='average')均可对s3分配平均排名,如图
5、如果要根据值在原Series的出现顺序排名,则需要使用s3.rank(method='first'),此处method=‘first’即可保证让值在原数据中的出现顺序进行排名,如图
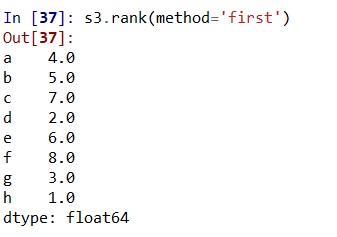
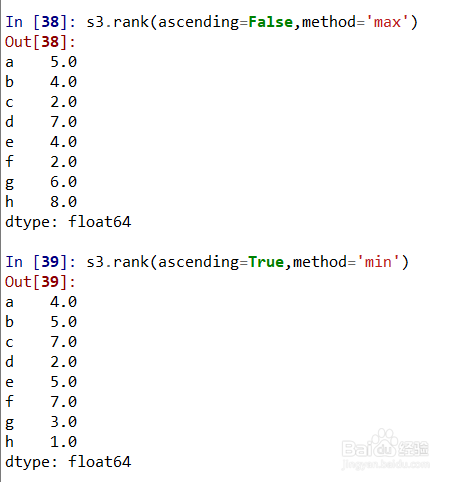
6、Series的降序排名和升序排名。
s3.rank(ascending=False,method='max')表示s3降序并按分组最大排名;s3.rank(ascending=True,method='min')表示s3升序并按分组最小排名;
如图