1、下文通过一段测试文本,说明BeaufulSoup的使用方法.首先导入模块:from bs4 import BeautifulSoup

2、使用BeautifulSoup解析这段代码,能够获取该模块的对象,而且能够得到一个标准缩进结构的格式化输出.

3、有了BeautifulSoup格式化的输出,我们可以简单测试下BeautifulSoup对性的属性,从下图可知,读入的txt是被BeautifulSoup模块转换为unicode编码形式了.
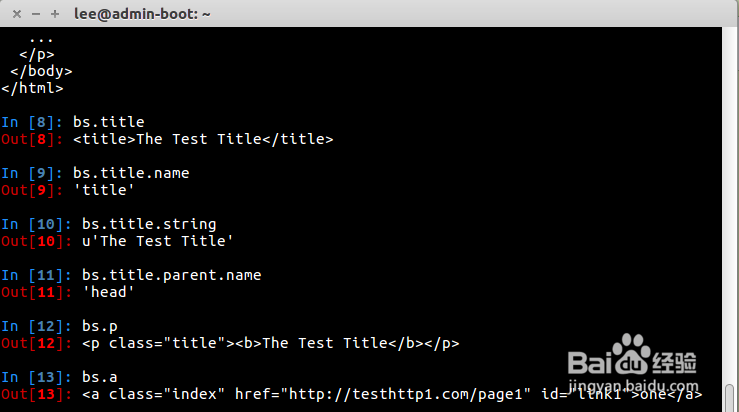
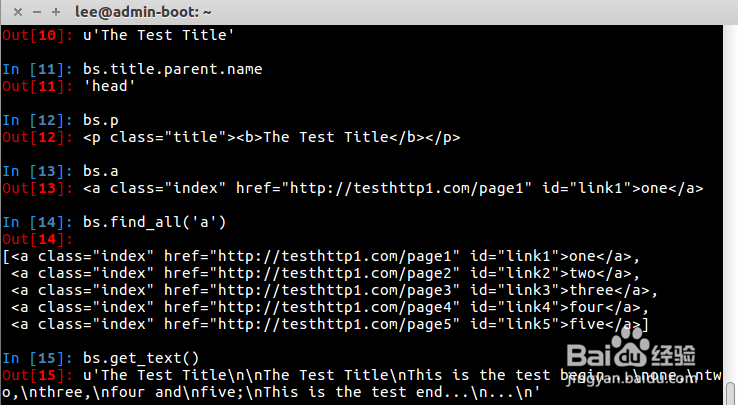
4、再来看下BeautifulSoup模块常用的函数方法.
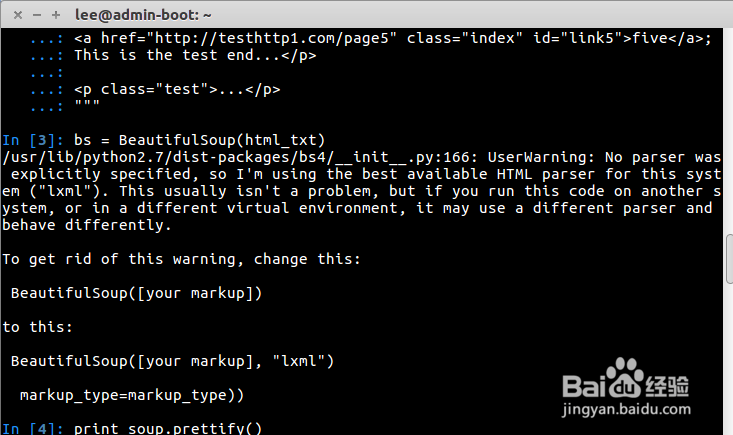
5、初次使用bs = BeautifulSoup(html_txt)会有如下告警,提示可以用不用的html解析器来处理.
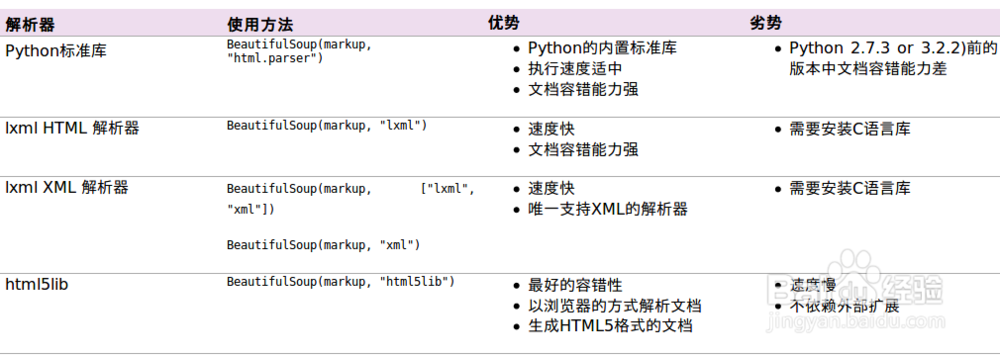
6、以下是主要的解析器和优缺点.
7、下图是不同的解析器之间的区别.可以看到字符:<b />,用python默认的解析器以及lxml解析器解析后会自动补齐<b></b>,但xml解析器则不会,由此可看到,如果被解析的HTML文档是标准格式,那么解析器之间没有任何差别,只是解析速度不同,结果都会返回正确的文档树.如果不是标准格式,那么不同的解析器返回结果可能不同.
