1、前提:加载numpy,pandas和Series,DataFrame。
生成一个层次索引的Series,命名为s1,如图

2、使用s1.index可以查看MultiIndex索引的层次化索引;
使用s1['c']查看腊总外层是‘c’的数据;
使用s1['b':'c']查激常看外层是‘b’和‘c’的数据(连续);
如图

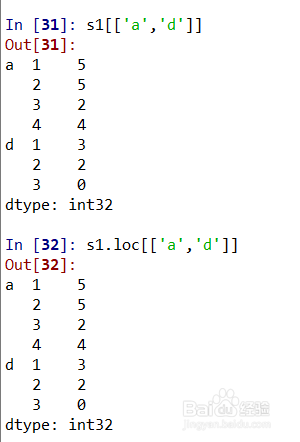
3、如果外层两个索引不连续,那么需要使用s1[['a','d']]或者s1.loc[['a','d']]即可取出外层索引为‘a’和‘d’的数据,如图所示
4、如果需要取出内层为‘2’的数据,那么使用s1[:,'2']即可,如图

5、层次化索引的重塑(类似excel的数据透视表)功能。
s1.unstack(level=-1)和s1.unstack(level=0)分别是表示将内层和外层耕缝距转化为列;unstack的逆运算是stack,具体如图


