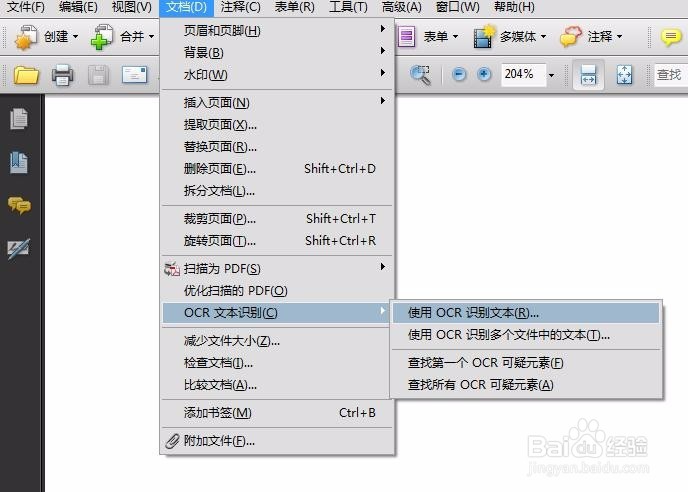
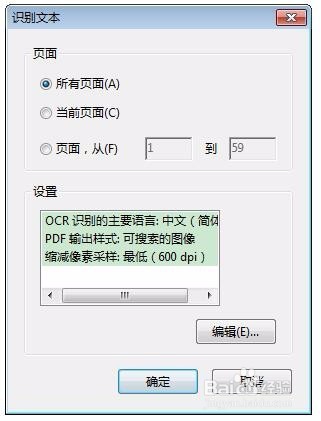
1、用Adobe Acrobat 9 Pro打开要进行操作的PDF文件,按下图所示步骤进行OCR文件识别。
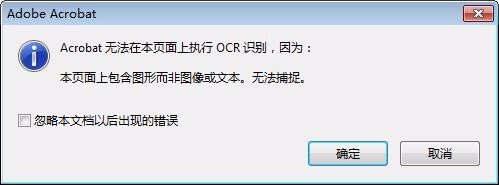
2、结果,却提示“Acrobat无法在本页面上执行OCR识别”
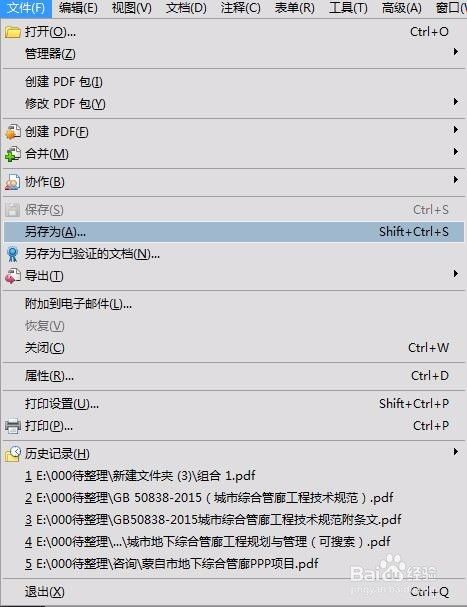
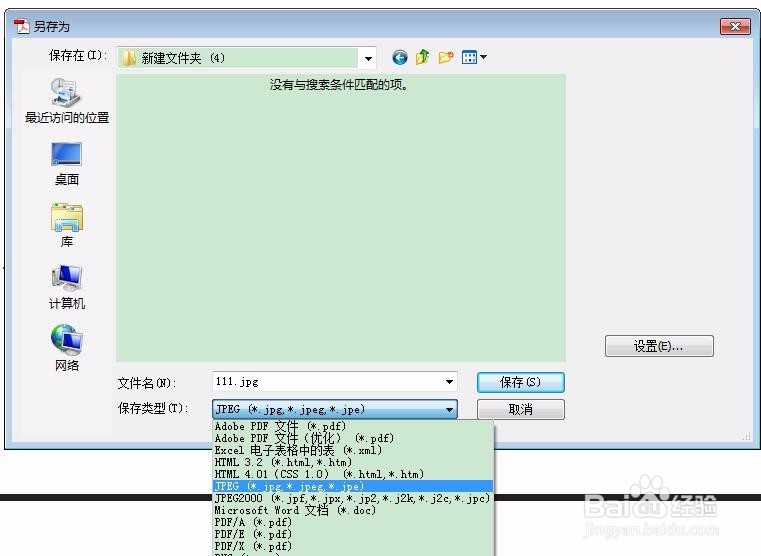
3、我的方法是,把该PDF文件另存为jpeg格式的图片文件(当然其他支持的图片格式也可以)。步骤见下图。

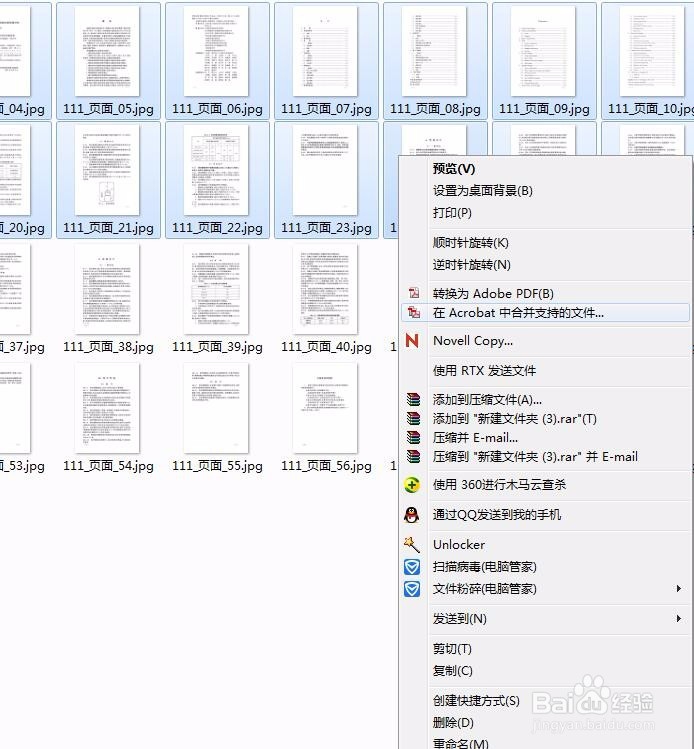
4、选择刚生成的所有图片,或者选择部分自己想要合成PDF的图片。
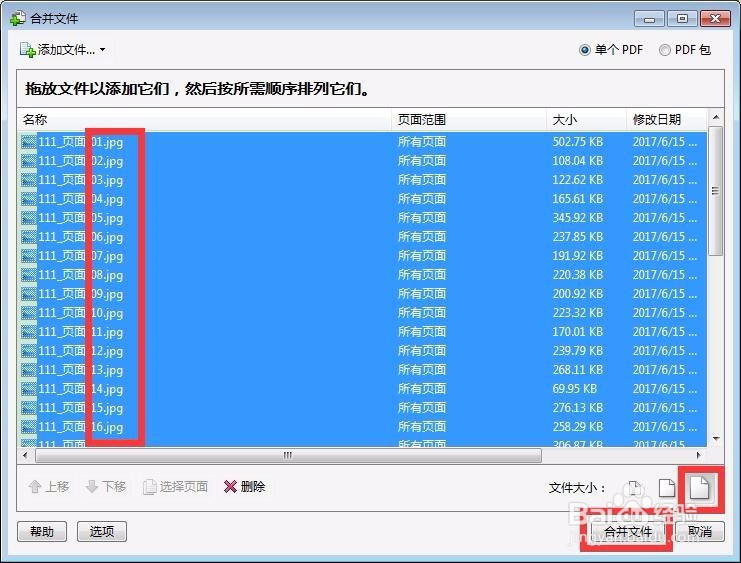
右键,选择合成PDF文件。步骤如下图所示。
5、然后再进行OCR文本识别,可以看到,这一下成功了,文件内容可以文本搜索也可以文字复制了。
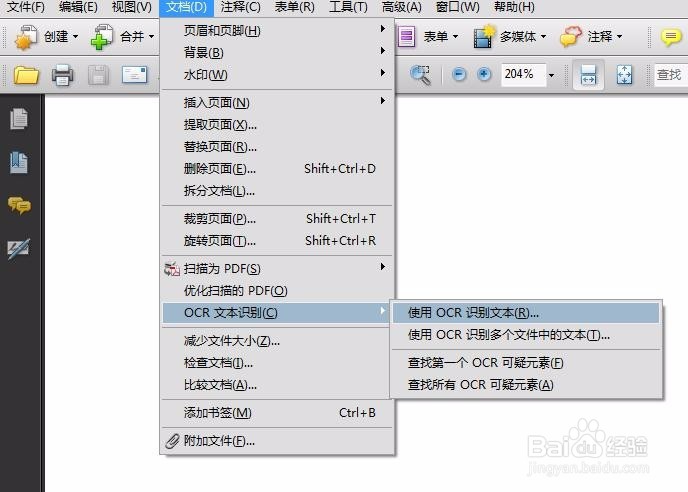

1、用Adobe Acrobat 9 Pro打开要进行操作的PDF文件,按下图所示步骤进行OCR文件识别。
2、结果,却提示“Acrobat无法在本页面上执行OCR识别”
3、我的方法是,把该PDF文件另存为jpeg格式的图片文件(当然其他支持的图片格式也可以)。步骤见下图。
4、选择刚生成的所有图片,或者选择部分自己想要合成PDF的图片。
右键,选择合成PDF文件。步骤如下图所示。
5、然后再进行OCR文本识别,可以看到,这一下成功了,文件内容可以文本搜索也可以文字复制了。