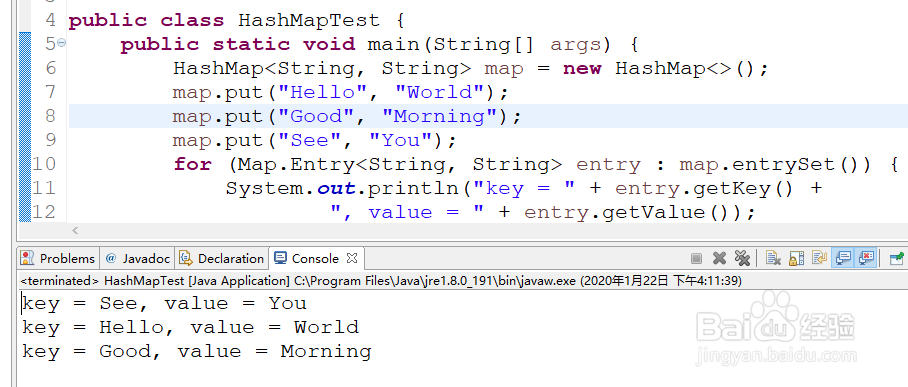
1、启动Eclipse开发工具,添加HashMap的测试用例,创建HashMap对象并且向其中添加数据,最后打印HashMap内部的数据,可以看出HashMap取出的数据顺序已经完全乱序
2、接着使用LinkedHashMap创建映射对象,同样添加数据,打印出LinkedHashMap内部的数据,可以看出打印出来的数据和添加进去的数据完全是相同的

3、点击LinkedHashMap查看其源代码会发现LinkedHashMap本身就是继承自HashMap,因而HashMap的功能它都会提供,接着查看它的构造方法可以看到其中有一个accessorder也就是访问顺序变量
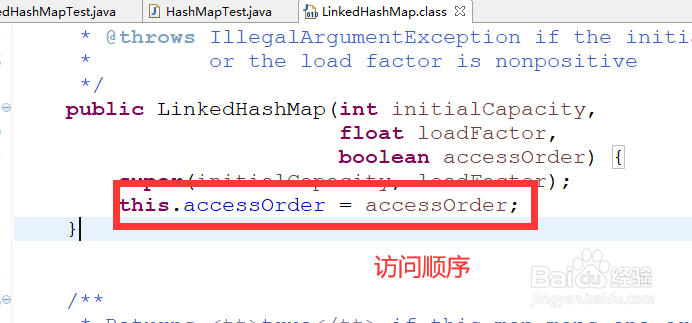
4、前面使用LinkedHashMap默认构造方法实际上accessOrder为false,也就是按照保存顺序,保存之后用户访问并不会改变数据保存的顺序,使用如图的代码在放入数据后访问一下,结果数据还是保持保存顺序不变

5、接着使用容量、加载因子和访问顺序的构造器,传入accessOrder为true表示内部的数据按照访问顺序排列,在放入数据后再随机访问,此时打印可以看到越新访问的数据越靠后

6、LinkedHashMap里面保存的数据都使用了双向链表来保存,保存时会按照保存顺序设置链表节点的before和after引用值,访问的时候按照after索引值查找后续节点保证了内部数据的顺序性

7、LinkedHashMap在get()访问数据时发现设置了accessOrder属性,就会将当前访问的节点放到双向链表的最后,也就保证了最后的节点是最新访问节点。按照访问顺序保存数据方便实现LRU算法,比如LruCache实际上就是继承自LinkedHashMap实现了LRU缓存算法。