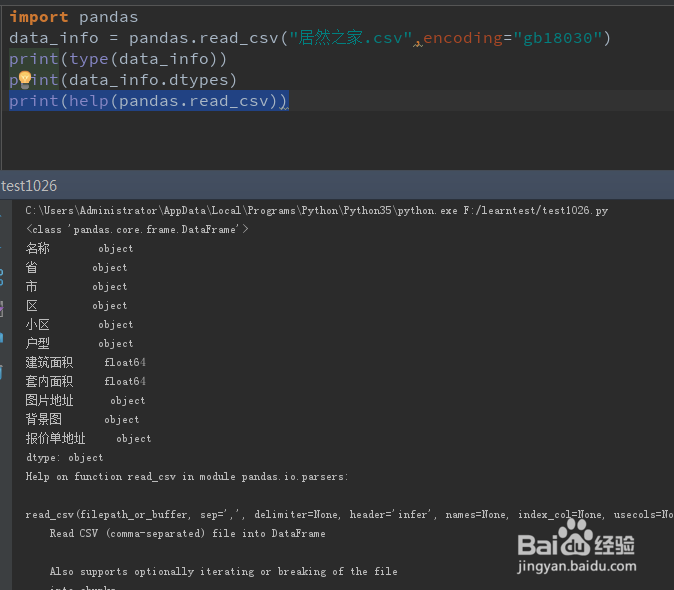
1、编写下图代码,其中最主要的方法是read_csv 因为我的文档和脚本在一个文件夹下,所以第一个参数只要写文件名就可以了,为了防止出现特殊字符的编码错误,可以用encoding = “gb18030”进行编码。
print(type(data_info)) 打印 data_info这个pandas对象的类型,可以看到是一个DataFrame对象。
print(data_info.dtypes) 打印了数据的各个列的数据类型,这里要注意字符串都是一个object类型,数字和小数是int64和float64的类型。
print(help(pandas.read_csv)) 利用help方法我们可以看看read_csv这个方法的具体参数要求。
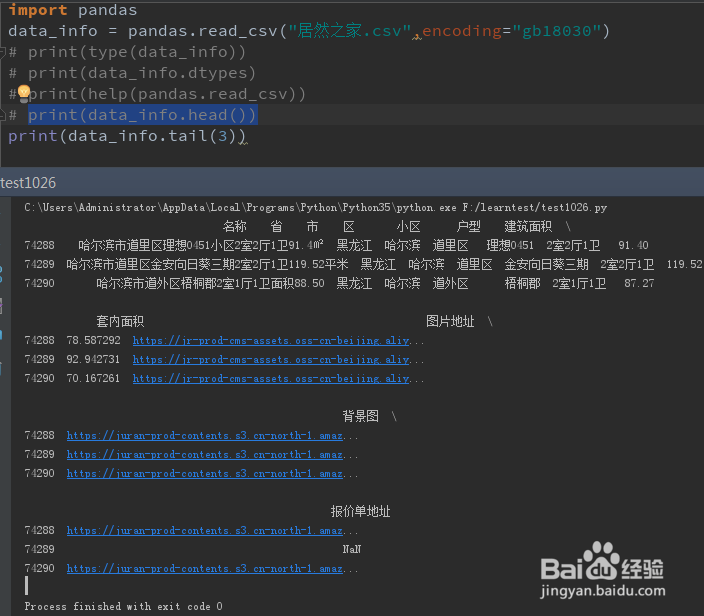
2、上一步将csv文件的数据读取到data_info对象中之后,我们可以简单的预览数据
print(data_info.head()),如果head()中没有任何参数的话,默认读取前5行记录。
同样的print(data_info.tail(),读取后5行的数据。

3、前两步可以对数据局部有个具体的预览,通过使用columns和shape方法可以对数据整理情况有一个很好的了解。
print(data_info.columns) 打印数据的行字段情况
print(data_info.shape) 打印数据的行数和列数
每一条记录有11个字段,总共有74291条记录

