1、创建Mysql数据库连接
1)登陆之后点击数据源(Source) ->数据库(Databases)
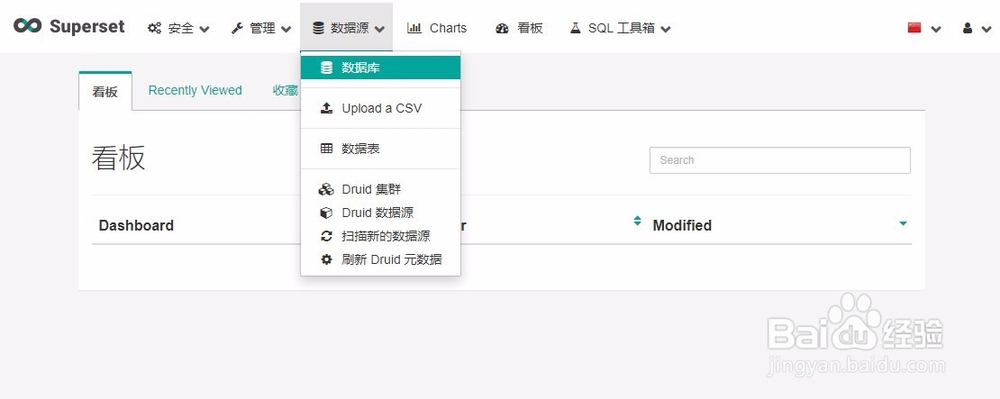
2、2)点击右上角加号(+)添加数据源
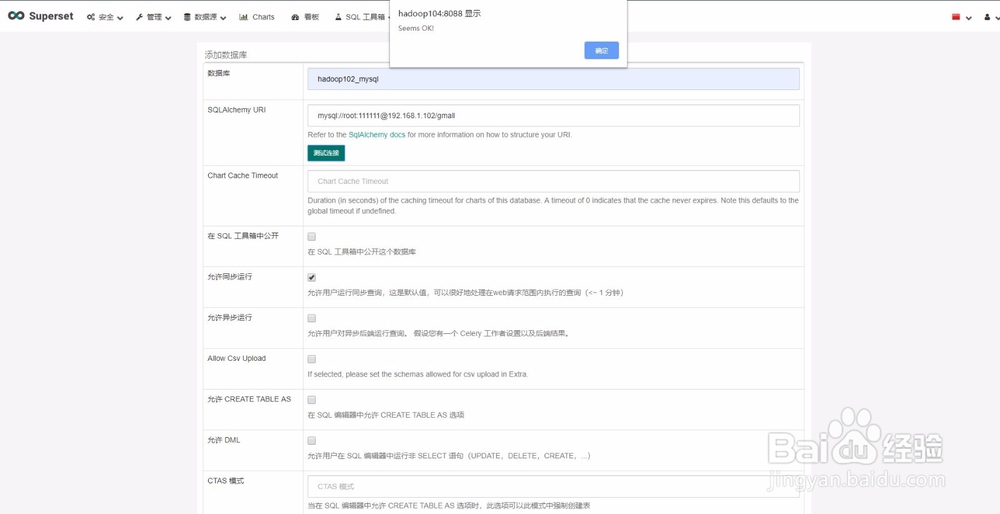
3、3)添加Mysql数据
1.SQL Alchemy URI编写规范:mysql://账号:密码@IP/数据库名称
2.点击测试连接,出现“Seems OK!”表示连接成功,下方展示出所有表名称。
3.勾选“在SQL工具箱中公开”,可以使用SQL语句查询。
4.其他根据需求进行勾选,无过多要求,随后点击最下方“保存(save)”。
4、4)添加成功
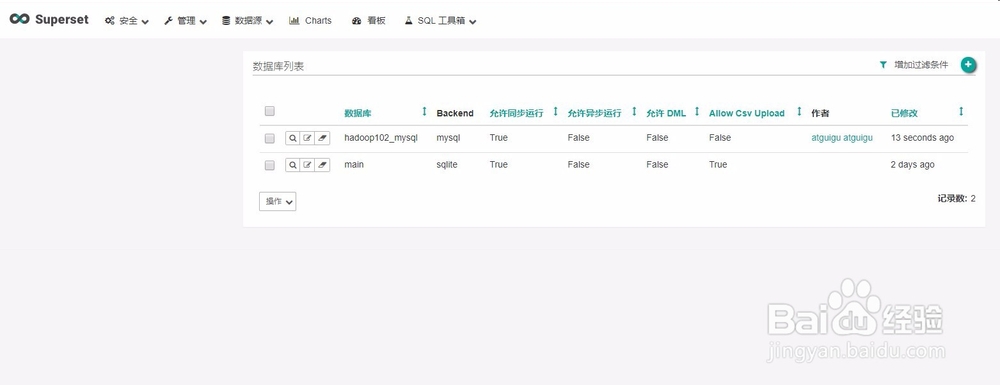
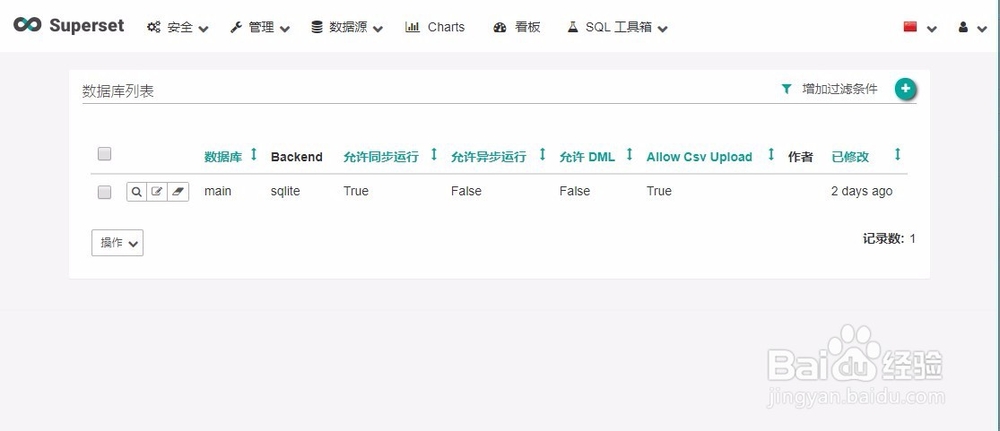
5、添加Mysql数据库的表格
1)添加数据表
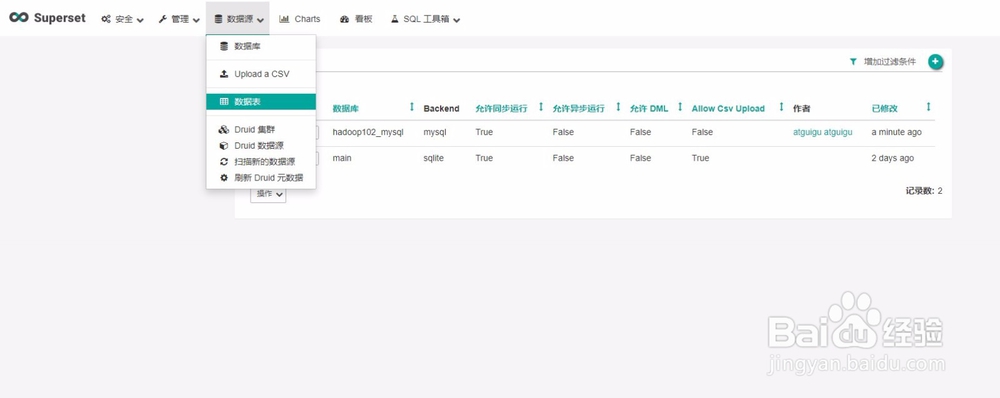
6、2)点击加号(+),添加表格,并保存
gmall数据库表格名称:base_category1 | base_category2 |base_category3 |order_detail |order_info |payment_info |sku_info |user_info
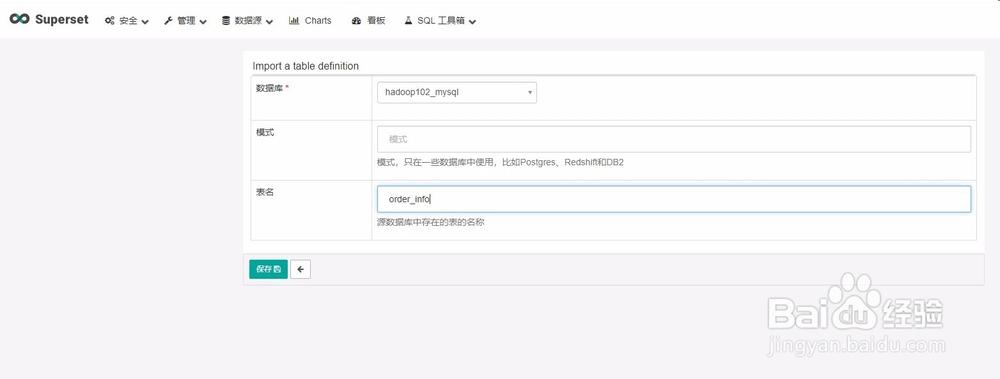
7、3)添加完成,可点击“过滤条件”选择不同维度对展示列表进行过滤。
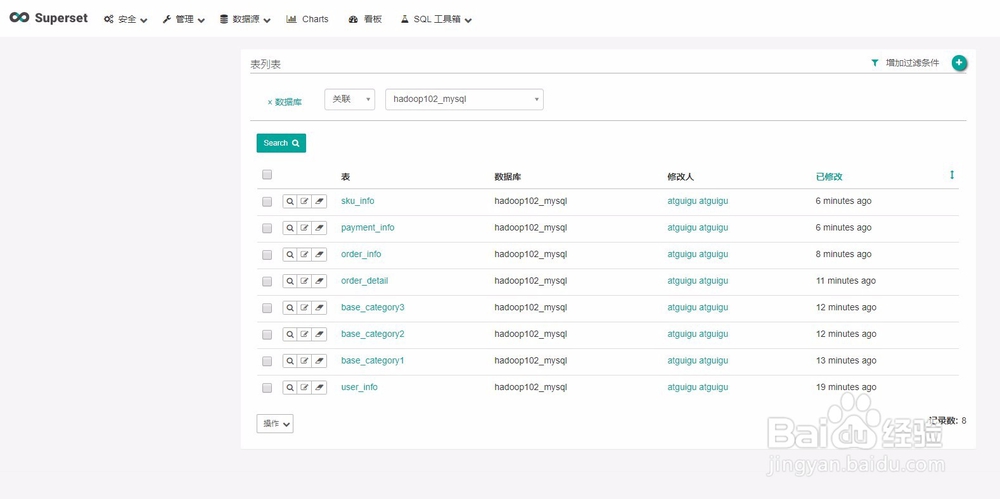
8、表的查看与编辑
1)点击编辑
9、2)列表展示
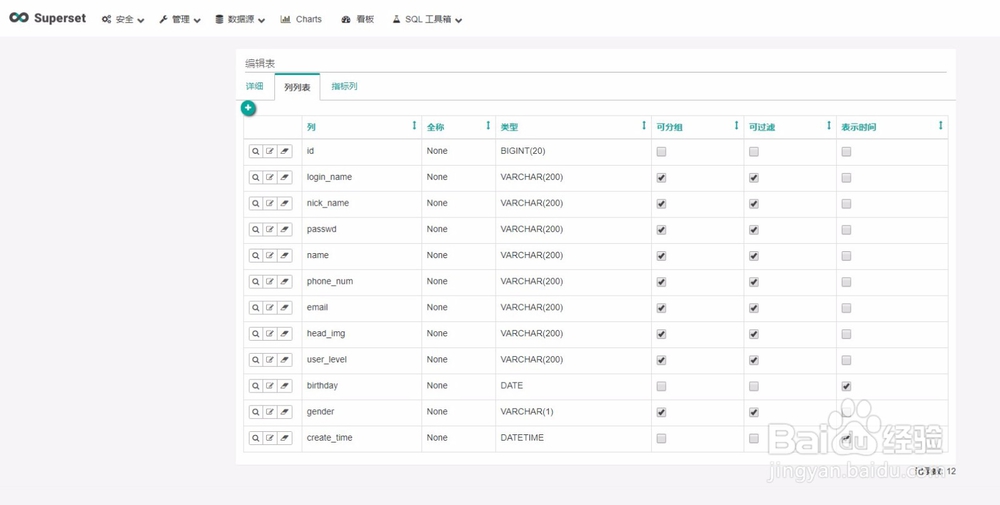
1. 在“详细”页中可通过sql语法对数据进行提前过滤操作,后续的操作基于本次查询的基础上进行实现。
2. 可对表结构、数据类型、是否可进行group、filter、count、sum、min、max操作等进行编辑。
3. 可通过sql语法添加一些新的列和列指标。
10、数据探索分析与可视化展示
方法一
点击下图中表的名称可进行表的查询过滤操作

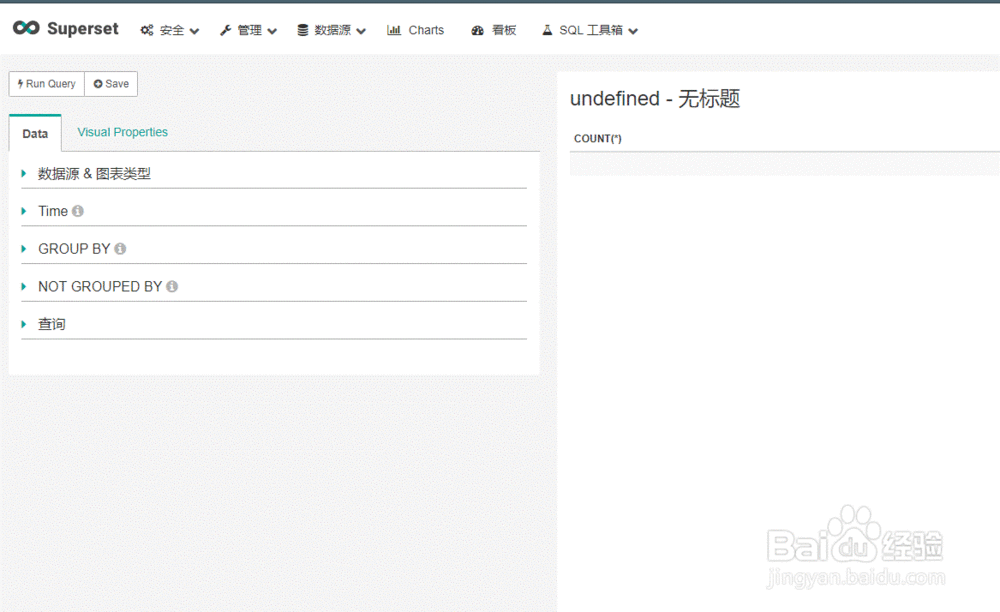
11、1)数据源&图表类型:可对数据源和图表的展示样式类型进行选择(有二十多种)。
2)Time:作为查询时的一个过滤条件。可以指定时间跨度,也可以以更加细化的粒度去划分(比如:时分秒)。
3)GROUP BY:x轴统计维度;Metrics:y轴展示的数据指标(包括指标的sum、avg等)
4)点击Run Query运行查询
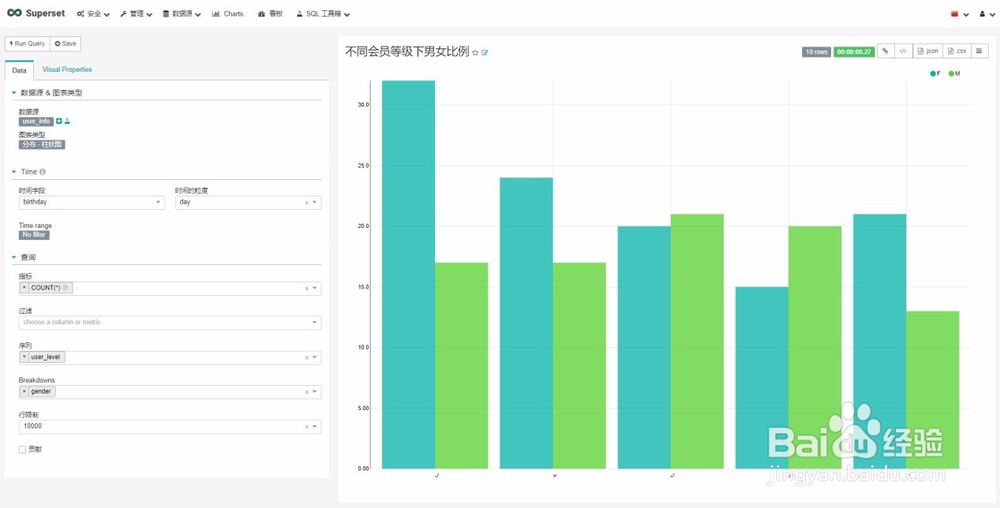
案例一:不同会员等级下男女比例
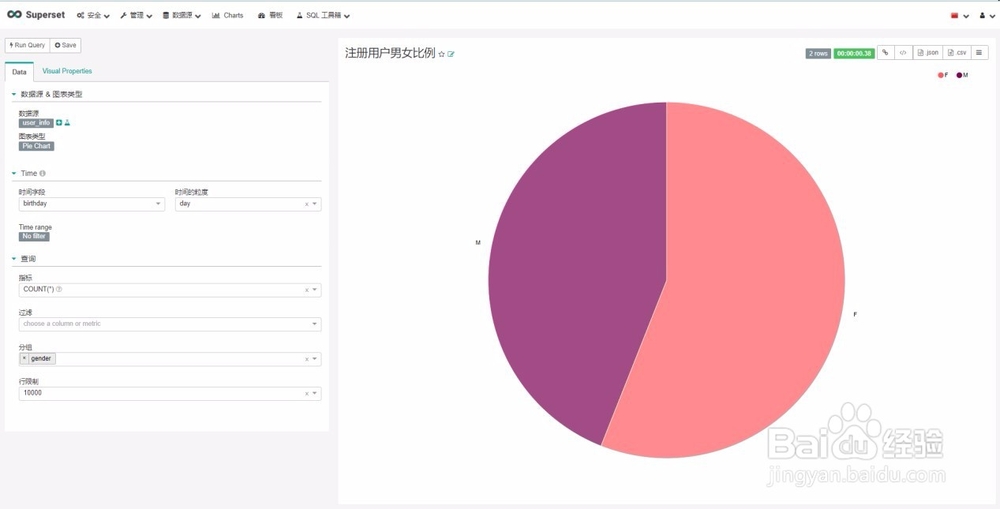
12、案例二:注册用户男女比例
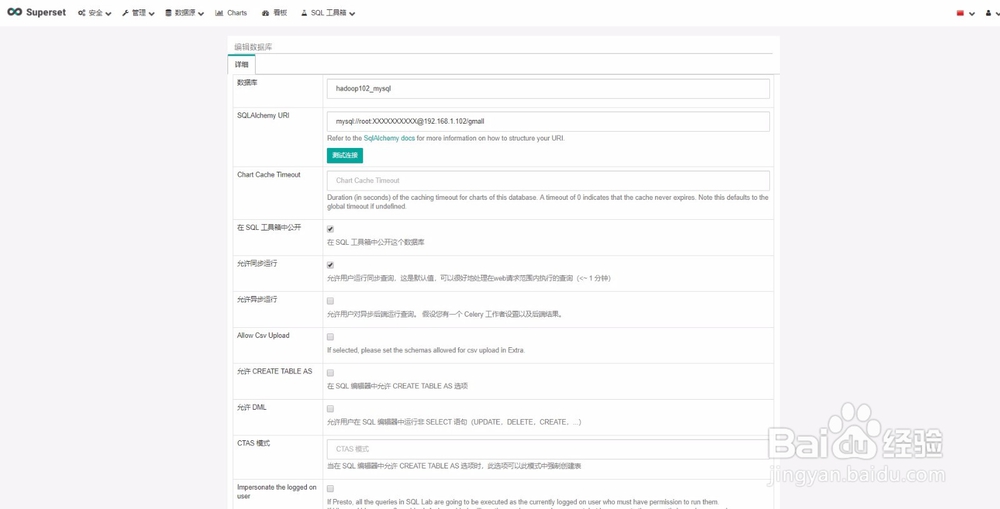
13、方法二
通过SQL查询,一定要在创建数据库连接时勾选“在SQL工具箱公开”。
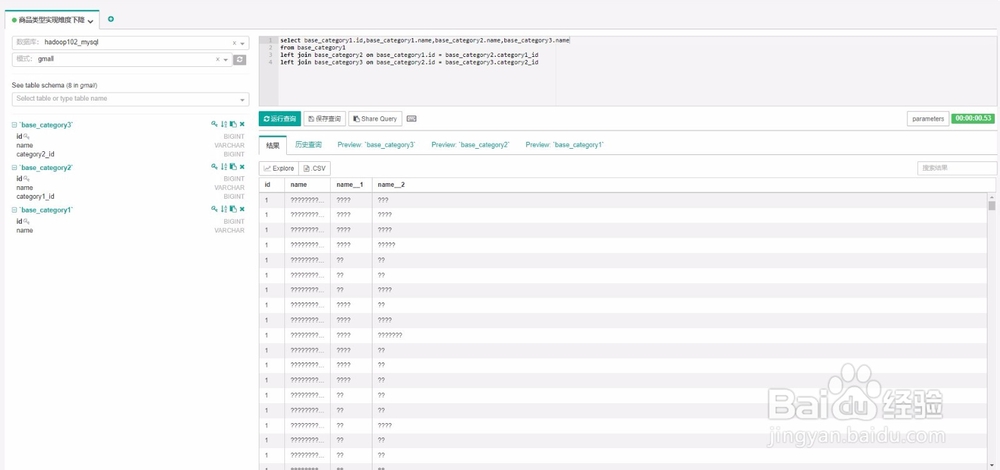
14、在SQLLib中可以执行任意符合当前数据库的sql语句。
案例三:
小试牛刀:对商品的分类表进行降维

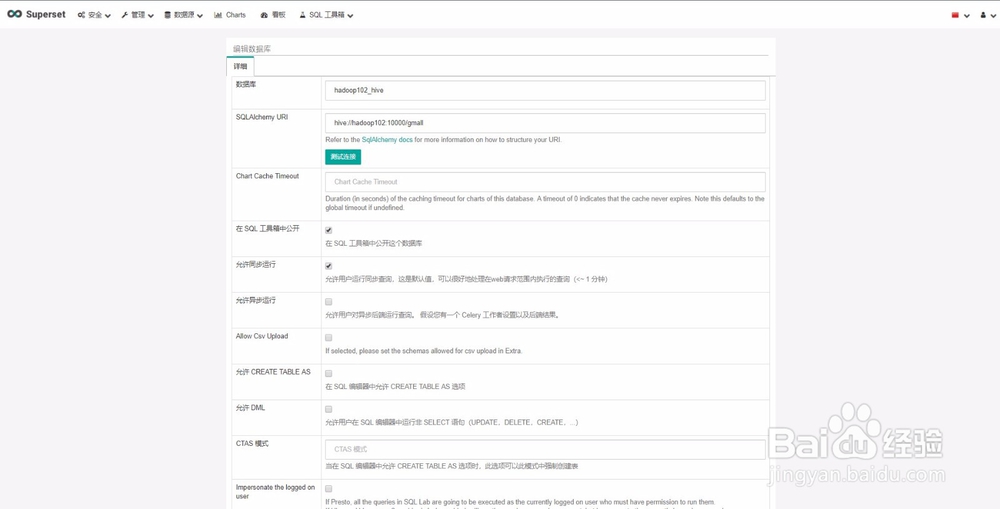
15、创建Hive数据仓库连接
1)在superset环境下安装pyhive库(pip install pyhive),并启动hadoop集群。
2)重点:一定要启动hiveserver2服务。
3)URI:hive://192.168.1.102:10000/gmall。
4)其它基本操作一样。
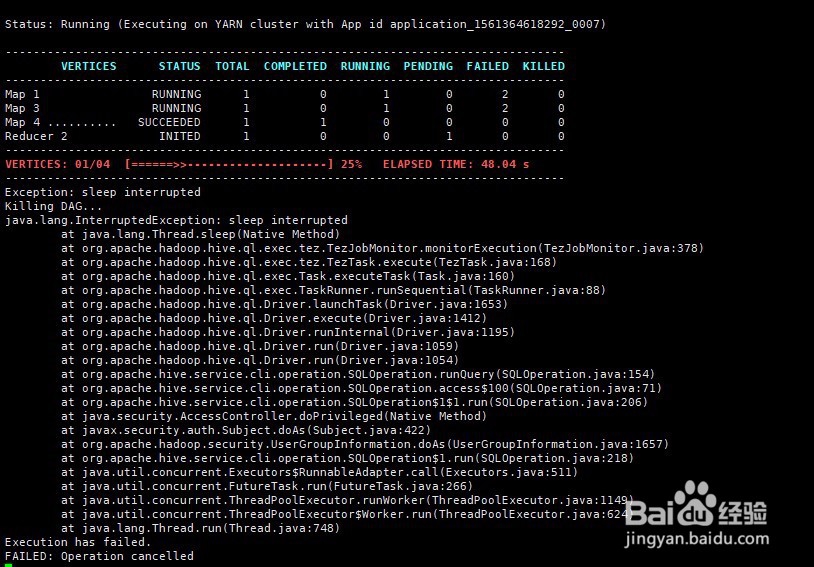
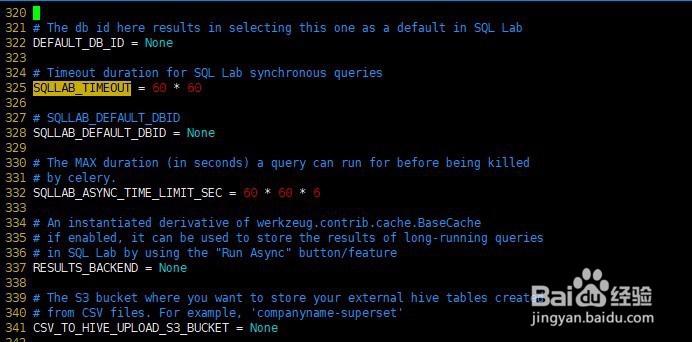
16、解决办法:
(superset) [atguigu@hadoop104 superset]$
vim /opt/module/anaconda3/envs/superset/lib/python3.6/site-packages/superset/config.py
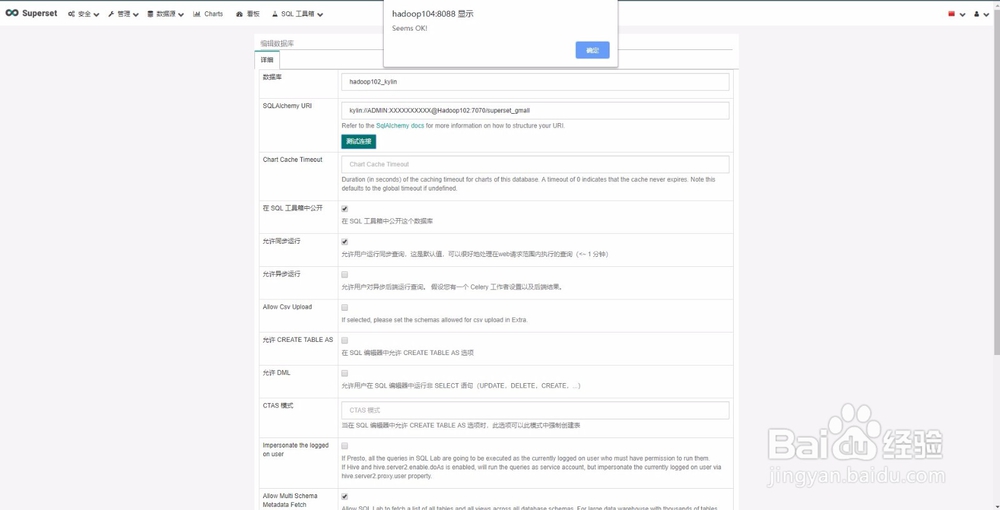
17、创建Kylin数据仓库连接
1)在superset环境下安装kylinpy库。
2)URI:kylin://ADMIN:KYLIN@192.168.1.102:7070/superset_gmall
3)其它都类似。