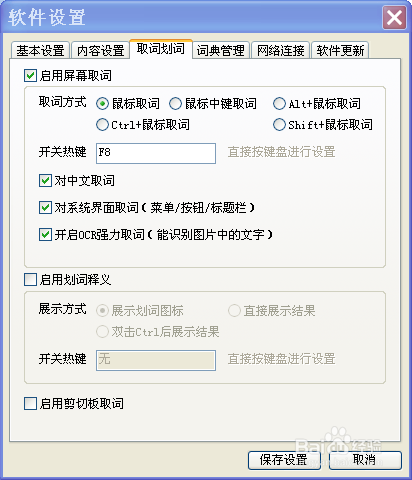
1、首先是取词,有道词典,软件设置,有个强力取词,基本可以解决单个词语的翻译。要下载那个OCR组件。
2、本人一般喜欢先把大段话复制到金山词霸在线翻译上,先翻译出个大概,再逐句翻译,所以现在需要解决复制的问题。听说adobe acrobat有文字识别,就在本单位网站上下载adobe acrobat pro 701下来,安装好,发现“文档”中“使用OCR识别文本”为灰色不可用,于是又去百度,原来OCR识别要自定义安装时,选中 查看Adobe PDF->Paper Capture (即OCR功能,Paper Capture下的罗马语言支持也要选上,我开始就是忽略了这个,结果又不可用)及亚洲语言支持,完成安装后用Acrobat 打开PDF图像,选择"文档"->"使用OCR识别文本"->"开始"。
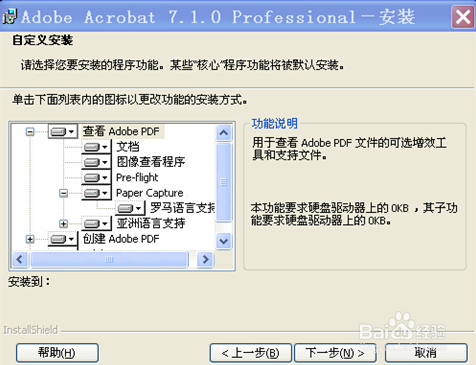
3、问题又出现了,无法识别,原因是超出了页面的最大范围,神马45英寸啥的。又去一顿搜,前辈们说要重新打印,用adobe pdf.
“文件”——“打印”,打印机名称选“adobe PDF”,页面的缩放方式:选择“缩小以适合打印机页边距”(最开始选择:“按PDF页面大小来选择纸张来源”,还是页面文件太大,弃选),再“自动旋转和居中”,这个好像关系不大。
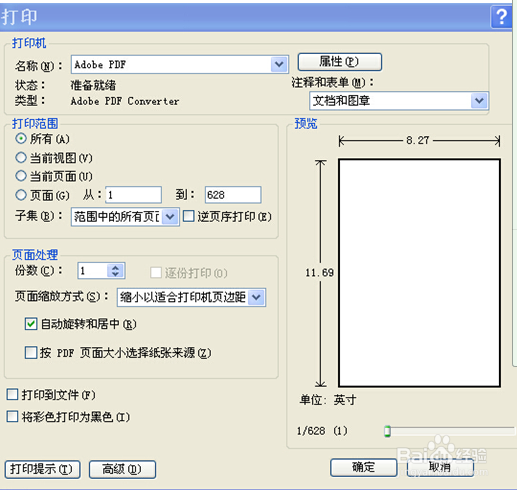
4、然后下边的“高级”里,作为图像打印,选600,我原来选的好像低,虽然打印成功,但是识别时说清晰度不够,无法识别。然后确定打印,可以只打印当前页一页,来看看打印成功没。打印成功后,再去用“使用OCR识别”
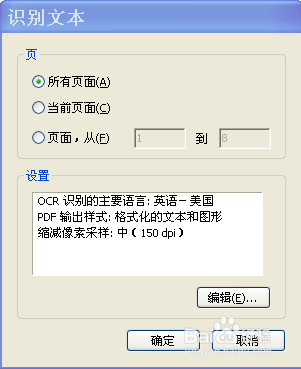
5、在弹出的"识别文本"对话框中,选择要转换的区域(全部页面,当前页面,自定义从第几页到第几页)。单击"编辑"按钮, "OCR识别的主要语言" 选"英语", "PDF输出样式"选择"格式化的文本和图形", "对图像缩减像素采样" 选合适的的dpi ,最低600.(4和5步骤里的像素选择我调整了n次,力图怎么样识别的最准确,最后自己蒙了,放弃了,总之你试着打印出来的能识别就好了)。
识别出来的也会有些不清楚的,有些词还是图片,总体而言是很少的