1、0.前言
0.1 抓取网页
本文将举例说明抓取网页数据的三种方式:正则表达式、BeautifulSoup、lxml。
获取网页内容所用代码详情请参照Python网络爬虫-你的第一个爬虫。利用该代码获取抓取整个网页。

2、0.2 爬取目标
爬取网页中所有显示内容。
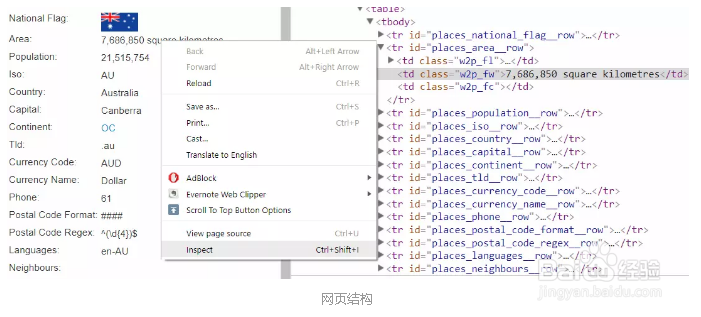
3、分析网页结构可以看出,所有内容都在标签<table>中,以area为例可以看出,area的值在:
<tr id="places_area__row"><td class="w2p_fw">7,686,850 square kilometres</td>
根据这个结构,我们用不同的方式来表达,就可以抓取到所有想要的数据了。

4、Chrome 浏览器可以方便的复制出各种表达方式:
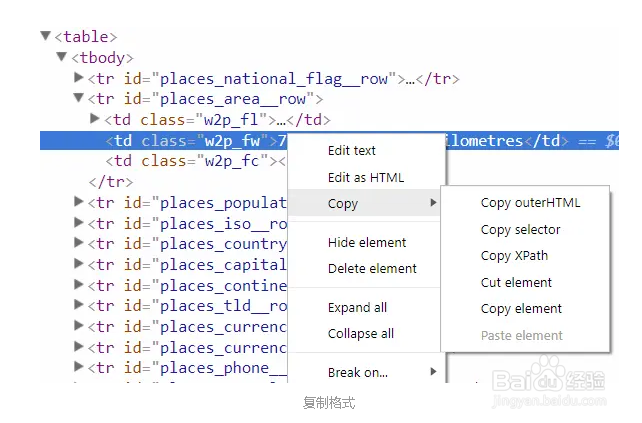
5、有了以上的download函数和不同的表达式,我们就可以用三种不同的方法来抓取数据了。
1.不同方式抓取数据
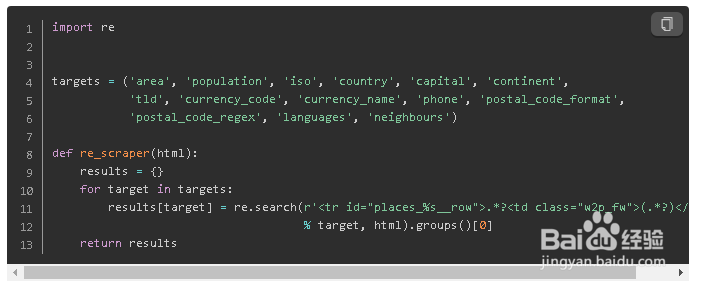
1.1 正则表达式爬取网页
正则表达式不管在python还是其他语言都有很好的应用,用简单的规定符号来表达不同的字符串组成形式,简洁又高效。学习正则表达式很有必要。 python内置正则表达式,无需额外安装。
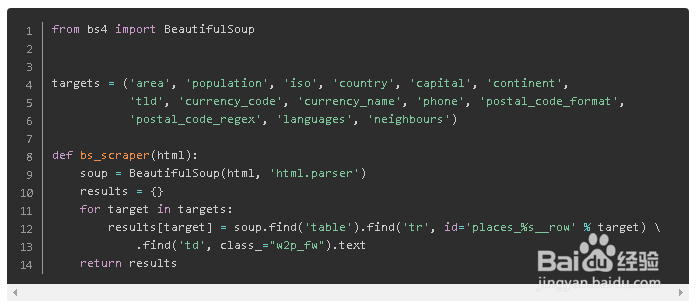
6、1.2BeautifulSoup抓取数据
BeautifulSoup用法可见python 网络爬虫 - BeautifulSoup 爬取网络数据
代码如下:
7、1.3 lxml 抓取数据
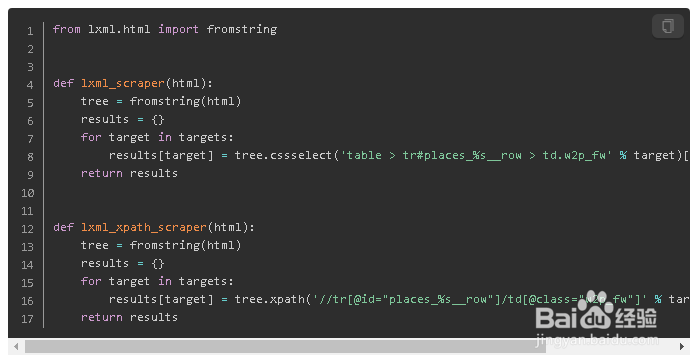
8、1.4 运行结果
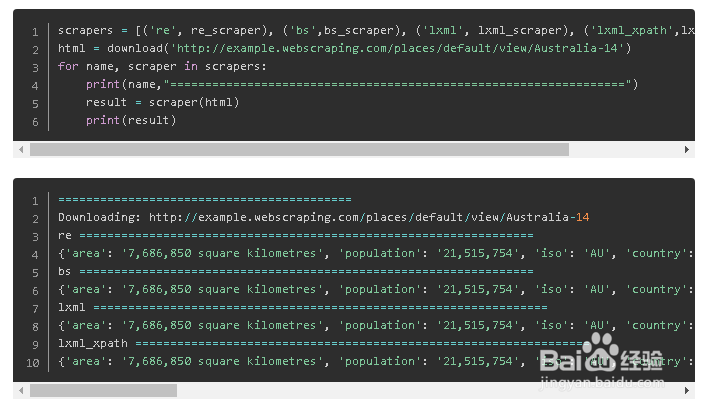
9、从结果可以看出正则表达式在某些地方返回多余元素,而不是纯粹的文本。这是因为这些地方的网页结构和别的地方不同,因此正则表达式不能完全覆盖一样的内容,如有的地方包含链接和图片。而BeautifulSoup和lxml有专门的提取文本函数,因此不会有类似错误。