1、python的安装推荐安装anaconda,自带jupyter notebook
上述基础工具安装完毕后,win + r打开控制台,输入pip install request 即可,如果速度过慢或者链接不上可以尝试pip install request -i https://pypi.tuna.tsinghua.edu.cn/simple/
同理bs4库的安装与request库的安装类似

2、安装完成后,控制台中输入pip list 即可查询到request库

3、正式开始我们的爬虫之旅~
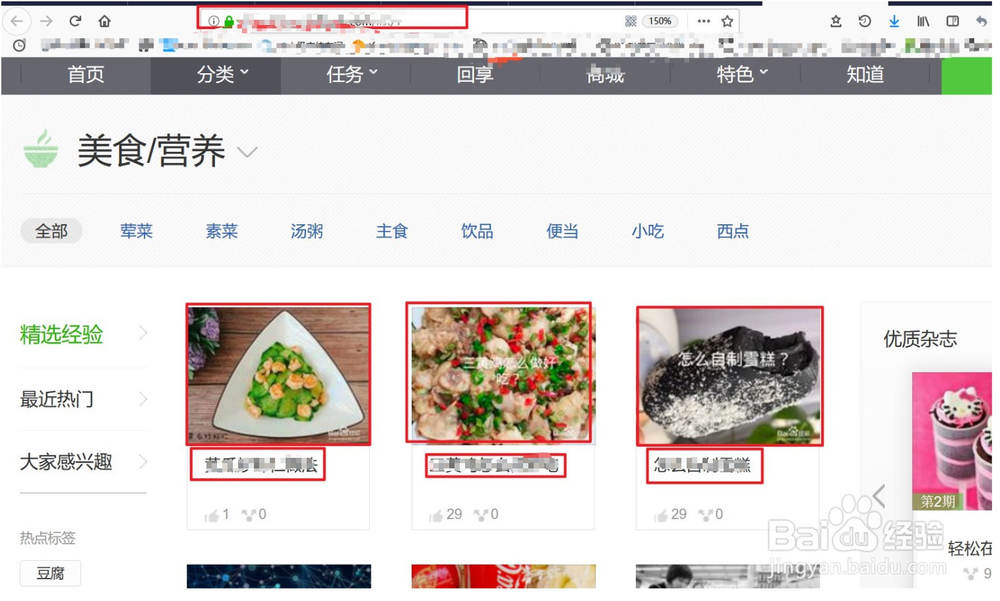
首先要明确我们想要爬取的目标~
对于网页源信息的爬取我们首先要获取url,然后定位我们的目标内容
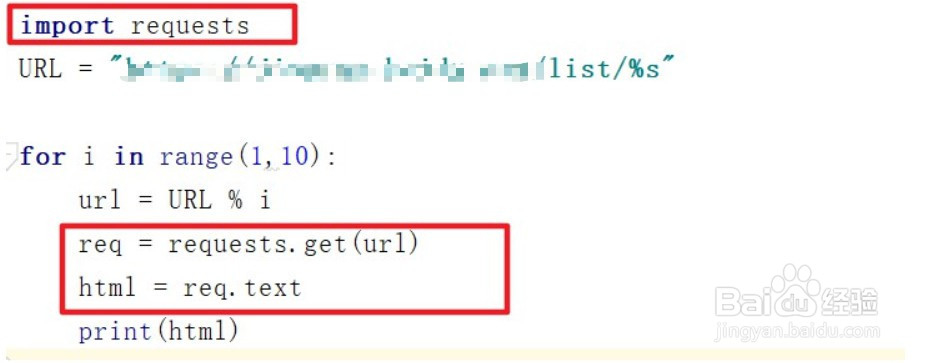
4、我们先使用基础for循环生成我们的url信息

5、然后我们需要模拟浏览器的请求(使用request.get(url)),获取目标网页的源代码信息(req.text)(注意需要在开头引入request库了)
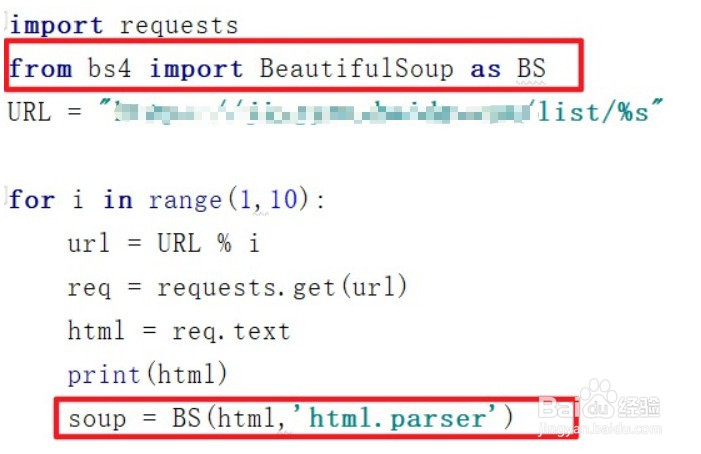
6、我们的目标信息就在源代码中,为了简单的获取目标信息我们需要用Beautifulsoup库对源代码进行解析,因为是html信息,我们采用html.parser的方式进行解析
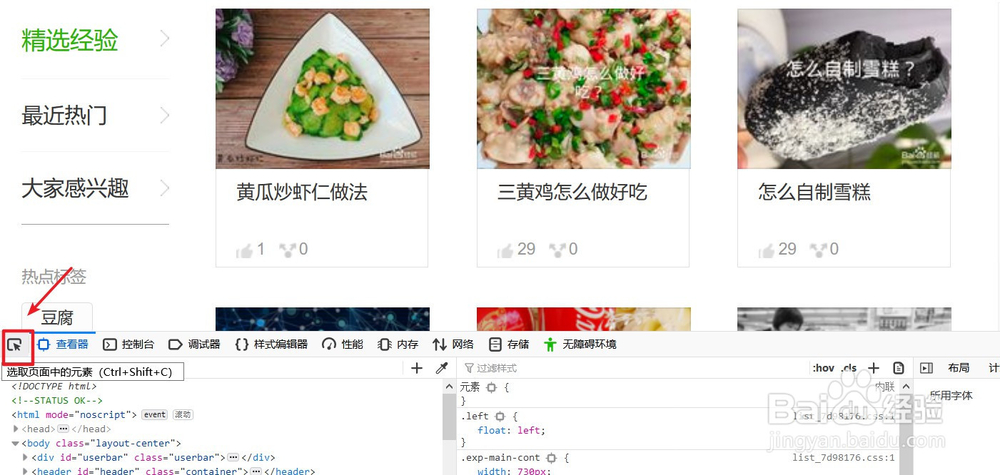
7、随后我们要在源网页中进一步定位目标信息在网页源代码中的位置:在网页中F12键,查看元素信息,使用左上角的按钮进一步查看目标信息位置
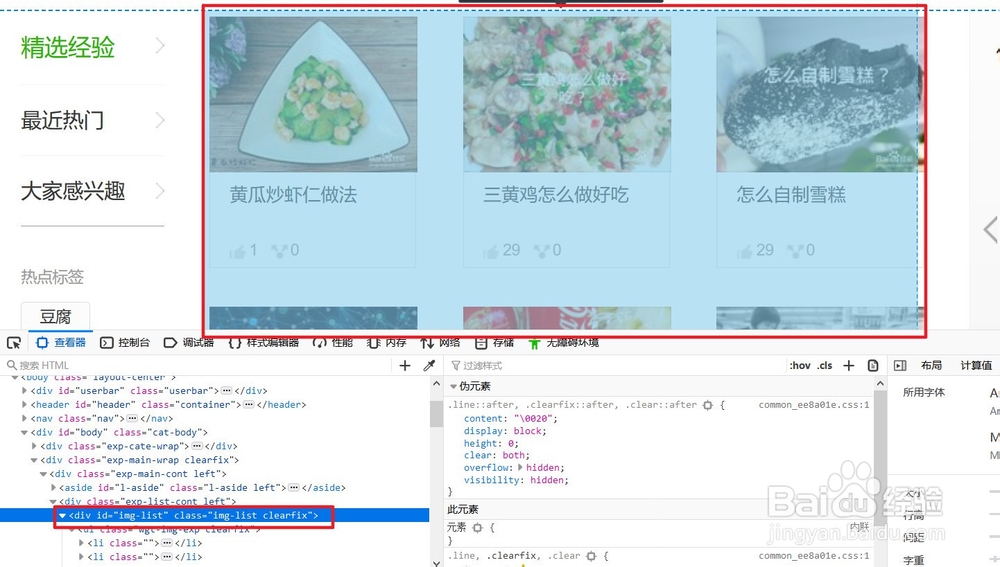
8、使用beautifulsoup进一步定位源代码信息
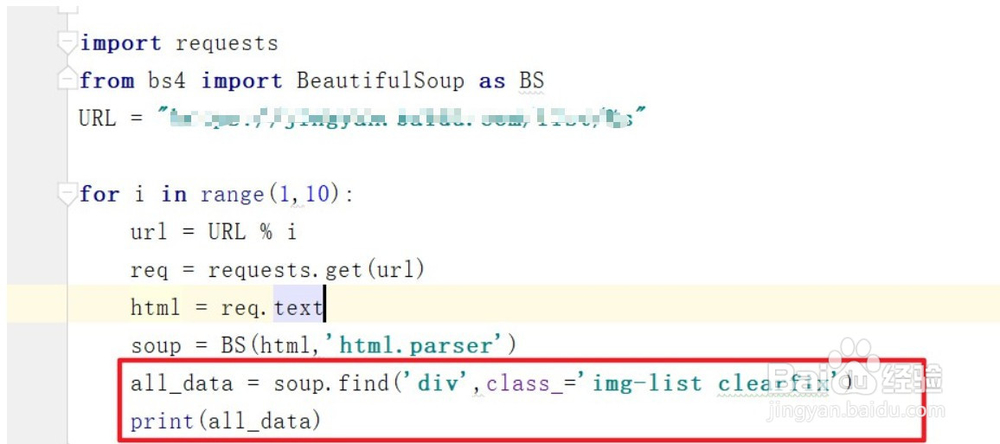

9、最后使用循环取出单个元素信息
首先分析单个信息的位置:他在ul列表下,使用循环取出
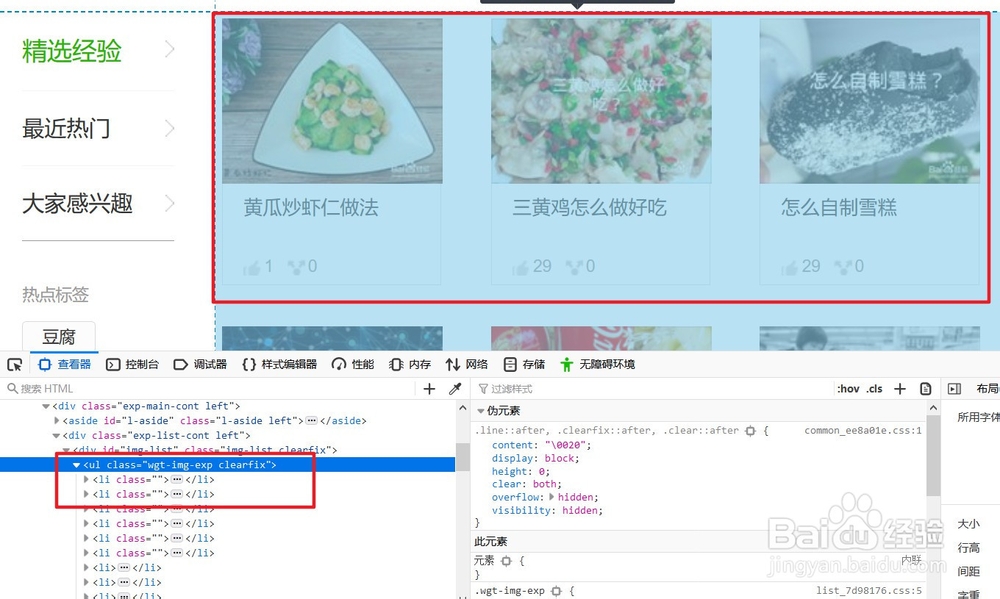

10、然后定位单个元素中信息的位置,并取出信息
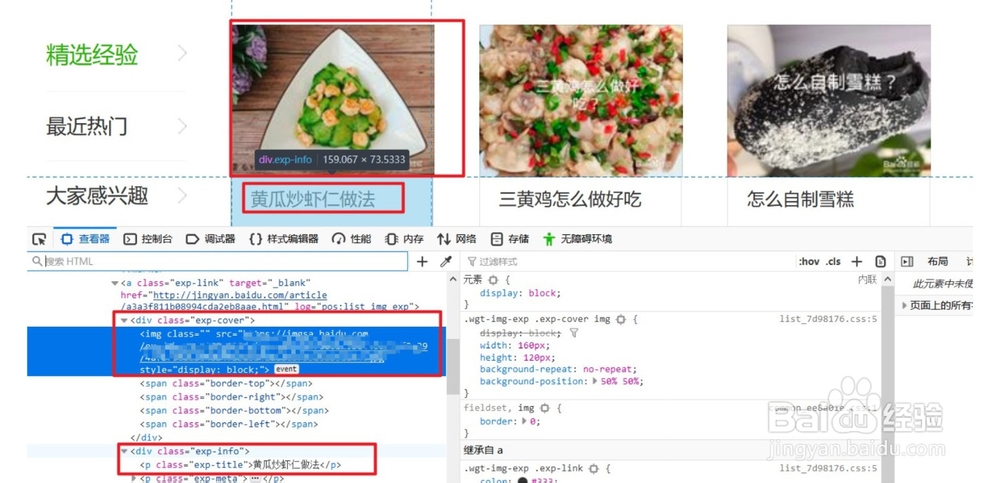
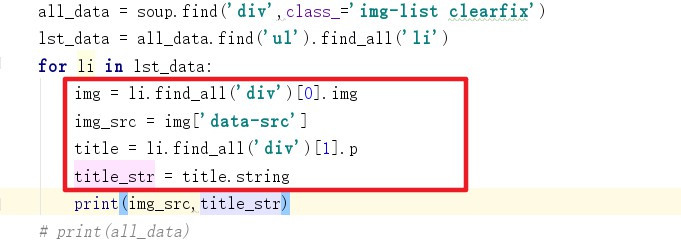
11、最终就得到了目标信息列表啦~
